|
Сравнительный анализ твердотельных накопителей с прозрачным сжатием
24, октябрь 2022 — Кейт Маккей ( Keith McKay ) , Что такое прозрачное сжатие? Прозрачное или встроенное сжатие действует как «ускоритель» для определенных рабочих нагрузок, что может показаться нелогичным. Но это имеет смысл, если вы понимаете, что происходит под капотом внутри флеш-памяти. Прозрачное сжатие сжимает данные во время записи во флэш-память и распаковывает их при чтении без каких-либо действий хоста. Хост может даже не знать, что это происходит внутри SSD. Прозрачное сжатие — это функция ускорения, которая может обеспечить более высокую производительность устойчивой случайной записи, меньшую задержку чтения в смешанных рабочих нагрузках и меньшее усиление записи для повышения надежности. Это устраняет многие компромиссы, возникающие при сжатии на основе ЦП, особенно в средах с большим количеством операций ввода-вывода в секунду. Основная предпосылка заключается в том, что, уменьшая активность записи во флэш-память, мы получаем следующие преимущества:
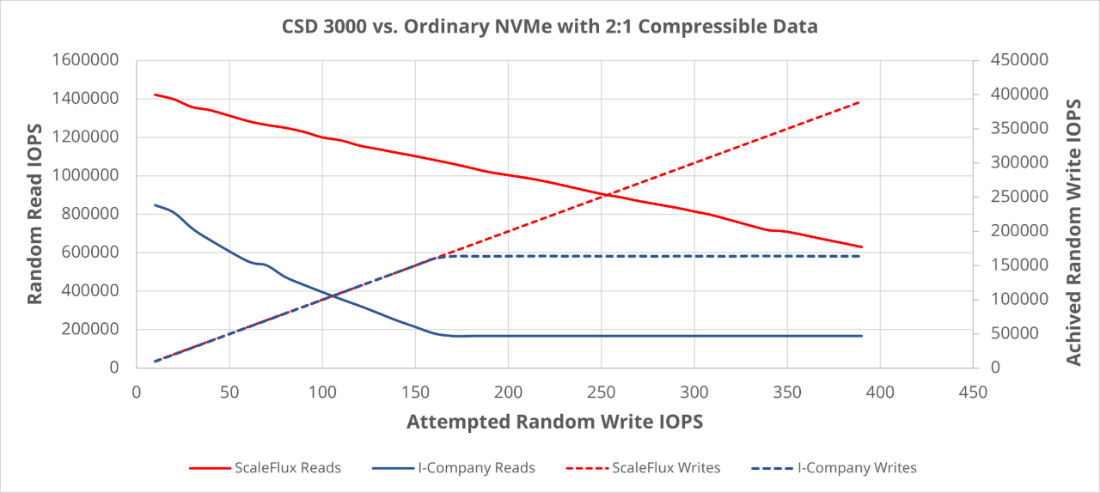
Как работает прозрачное сжатие? Для достижения значительного прироста производительности и долговечности не требуется слишком большой степени сжатия данных. Мы видим, что за пределами сжимаемости 2:1 наблюдается убывающая отдача, поскольку данные хоста физически занимают менее половины доступного носителя, поэтому сборка мусора может работать практически без перемещения данных. Еще одним результатом сжатия является эффективное увеличение дополнительной избыточной подготовки (OP) для SSD. Рынок вращается вокруг емкостей 7% OP с «интенсивным чтением» и 28% OP с «интенсивной записью» (например, 3,2 ТБ против 3,84 ТБ) , которые отличаются всего на 20% свободного места, поэтому коэффициент сжатия 1,2: 1 может превратиться диск с «интенсивным чтением» в «интенсивный по записи». По совпадению, мы обычно можем дополнительно сжать сжатые данные LZ4 (или Snappy) примерно на 20% (через нашу стадию кодирования Хаффмана). А как насчет емкости твердотельных накопителей ScaleFlux? Если данные сжимаемы, мы можем вернуть хосту дополнительную емкость. Мы делаем это с помощью набора функций NVMe Thin Provisioning, где мы можем установить размер пространства имен больше, чем поддерживающая его физическая емкость. Физическое использование указывается в поле использования пространства имен и контролируется хостом. Это не компромисс или/или с повышением производительности. Допустим, данные в среднем сжимаются 2:1; затем мы можем увеличить емкость с 3,84 ТБ до 6,2 ТБ и поддерживать уровень производительности OP на уровне 28%. Чтобы получить наилучшие результаты, сосредоточьтесь на смешанных рабочих нагрузках чтения/записи и задержке. При тестировании диска с прозрачным сжатием мы ищем рабочие нагрузки со смешанными операциями чтения и записи. Мы оцениваем производительность на основе результатов задержки и IOPS для данных, хранящихся с различными уровнями сжатия, от несжимаемых до сжатых примерно до 2,5:1. Любая дальнейшая сжимаемость должна применяться к расширению емкости. Например, у нас есть тест, в котором мы постоянно увеличиваем количество случайных операций записи при максимальной производительности чтения:
Глядя на диаграмму выше, шкала ScaleFlux выделена красным цветом, а другой SSD Gen4 — синим. Сплошные линии — «Чтение IOPS», а пунктирные линии — «Достигнутое количество операций ввода-вывода в секунду при записи». По мере увеличения числа операций ввода-вывода при попытке записи наша производительность чтения снижается гораздо меньше, и мы также можем продолжать масштабировать количество операций ввода-вывода в секунду при записи линейно. Как диск сравнивается, если ваша рабочая нагрузка не использует преимущества сжатия? Данные будут обходить сжатие, если они не поддаются сжатию, что делает производительность SSD конкурентоспособной с ведущими твердотельными накопителями Gen4 NVMe на рынке. Другими словами, сжимаемость данных — это все с ног на голову. Лучшие практики тестирования Одна вещь, которую вы, возможно, захотите сделать во время тестирования емкости нашего диска, — загрузить исходную версию nvme-cli. Он имеет последнюю версию нашего плагина, который может легко сообщать об увеличении записи и общем коэффициенте сжатия на SSD (nvme sfx /dev/nvme… smart-log-add). https://github.com/linux-nvme/nvme-кли Наконец, наша среда FIO находится на GitHub. В нем есть несколько тестов, предназначенных для выявления преимуществ в производительности (включая данные для приведенного выше графика). В README есть таблица, отображающая настройки FIO в зависимости от степени сжатия (достигаемой приводом). https://github.com/kpmckay/fio-скрипты Я полагаю, что теперь у вас есть вся информация, необходимая для того, чтобы приступить к тестированию возможностей нашего накопителя. Не стесняйтесь обращаться ко мне в LinkedIn или по электронной почте в нашу команду по адресу info@scaleflux.com и запросить PoC . |
| ||||||||