|
NVIDIA DGX GH200: первая система памяти GPU на 100 терабайт
28, май 2023 — На выставке COMPUTEX 2023 NVIDIA представила NVIDIA DGX GH200 , которая знаменует собой еще один прорыв в вычислениях с ускорением на GPU для поддержки самых ресурсоемких гигантских рабочих нагрузок ИИ. В дополнение к описанию критических аспектов архитектуры NVIDIA DGX GH200 в этом посте обсуждается, как NVIDIA Base Command обеспечивает быстрое развертывание, ускоряет адаптацию пользователей и упрощает управление системой.
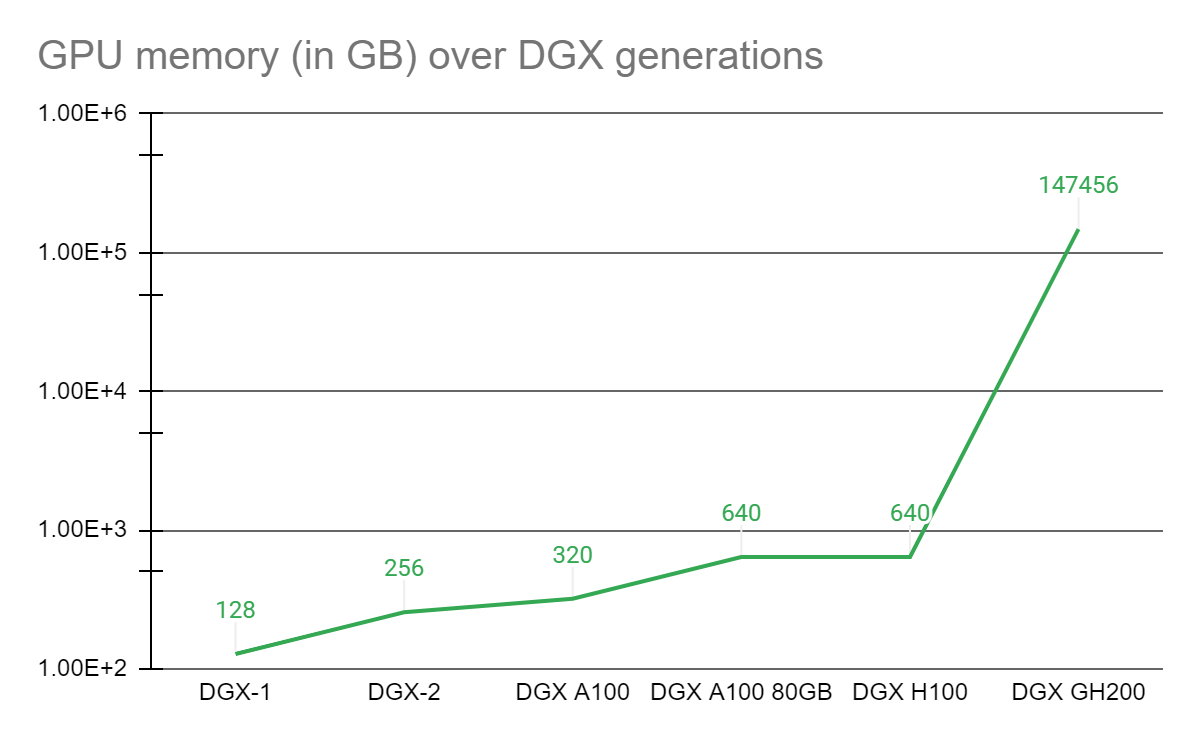
Унифицированная модель программирования памяти графических процессоров была краеугольным камнем различных прорывов в сложных приложениях ускоренных вычислений за последние 7 лет. В 2016 году NVIDIA представила технологию NVLink и модель унифицированного программирования памяти с CUDA-6, предназначенную для увеличения памяти, доступной для рабочих нагрузок с ускорением на GPU. С тех пор ядром каждой системы DGX является комплекс графических процессоров на базовой плате, соединенный с помощью NVLink, в котором каждый графический процессор может обращаться к памяти другого со скоростью NVLink. Многие такие DGX с комплексами GPU связаны между собой высокоскоростной сетью для формирования более крупных суперкомпьютеров, таких как суперкомпьютер NVIDIA Selene . Тем не менее, формирующийся класс гигантских моделей ИИ с триллионами параметров потребует либо нескольких месяцев для обучения, либо не может быть решен даже на лучших современных суперкомпьютерах. Чтобы помочь ученым, нуждающимся в передовой платформе, способной решить эти необычные задачи, NVIDIA объединила суперчип NVIDIA Grace Hopper с системой коммутации NVLink, объединив до 256 графических процессоров в систему NVIDIA DGX GH200. В системе DGX GH200 144 терабайта памяти будут доступны для модели программирования с общей памятью графического процессора на высокой скорости через NVLink. По сравнению с одной системой NVIDIA DGX A100 320 ГБ , NVIDIA DGX GH200 обеспечивает почти в 500 раз больше памяти для модели программирования с общей памятью графического процессора через NVLink, образуя гигантский графический процессор размером с центр обработки данных. NVIDIA DGX GH200 — первый суперкомпьютер, преодолевший барьер в 100 терабайт для памяти, доступной для графических процессоров через NVLink.
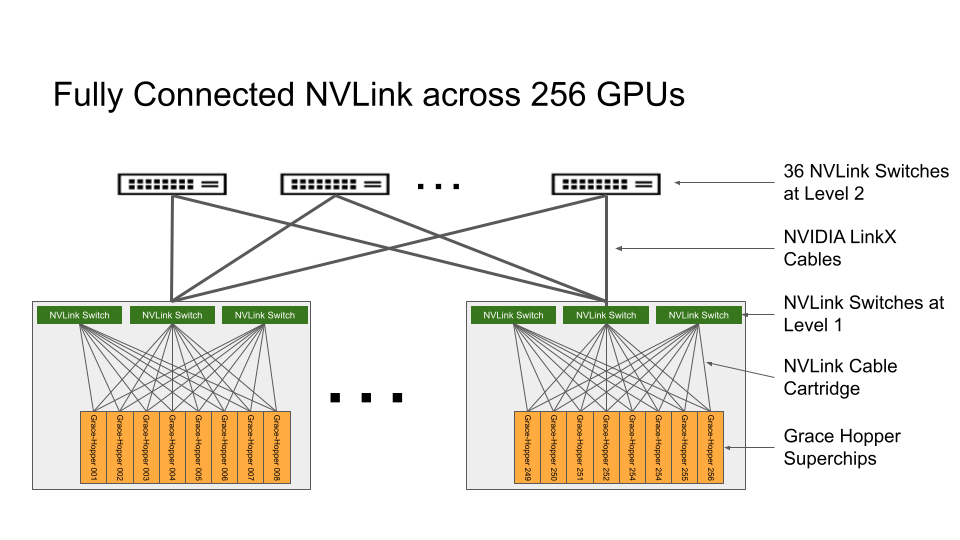
Рис. 1. Прирост памяти графического процессора в результате прогресса NVLink Системная архитектура NVIDIA DGX GH200Суперчип NVIDIA Grace Hopper и система коммутации NVLink являются строительными блоками архитектуры NVIDIA DGX GH200. Суперчип NVIDIA Grace Hopper сочетает в себе архитектуры Grace и Hopper с использованием NVIDIA NVLink-C2C для создания согласованной модели памяти CPU + GPU. Система коммутации NVLink, основанная на технологии NVLink четвертого поколения, расширяет соединение NVLink между суперчипами для создания бесшовной системы с несколькими графическими процессорами с высокой пропускной способностью. Каждый суперчип NVIDIA Grace Hopper в NVIDIA DGX GH200 имеет 480 ГБ памяти ЦП LPDDR5, что составляет восьмую часть мощности на ГБ по сравнению с DDR5 и 96 ГБ быстрой памяти HBM3. ЦП NVIDIA Grace и графический процессор Hopper связаны между собой с помощью NVLink-C2C, обеспечивая в 7 раз большую пропускную способность, чем PCIe Gen5, при мощности в пять раз меньше. Система коммутации NVLink формирует двухуровневую неблокирующую структуру NVLink с толстым деревом для полного подключения 256 суперчипов Grace Hopper в системе DGX GH200. Каждый графический процессор в DGX GH200 может получить доступ к памяти других графических процессоров и расширенной памяти графического процессора всех процессоров NVIDIA Grace со скоростью 900 Гбит/с. Вычислительные платы с суперчипами Grace Hopper подключаются к системе коммутации NVLink с помощью специального кабельного жгута для первого слоя матрицы NVLink. Кабели LinkX расширяют возможности подключения на втором уровне матрицы NVLink.
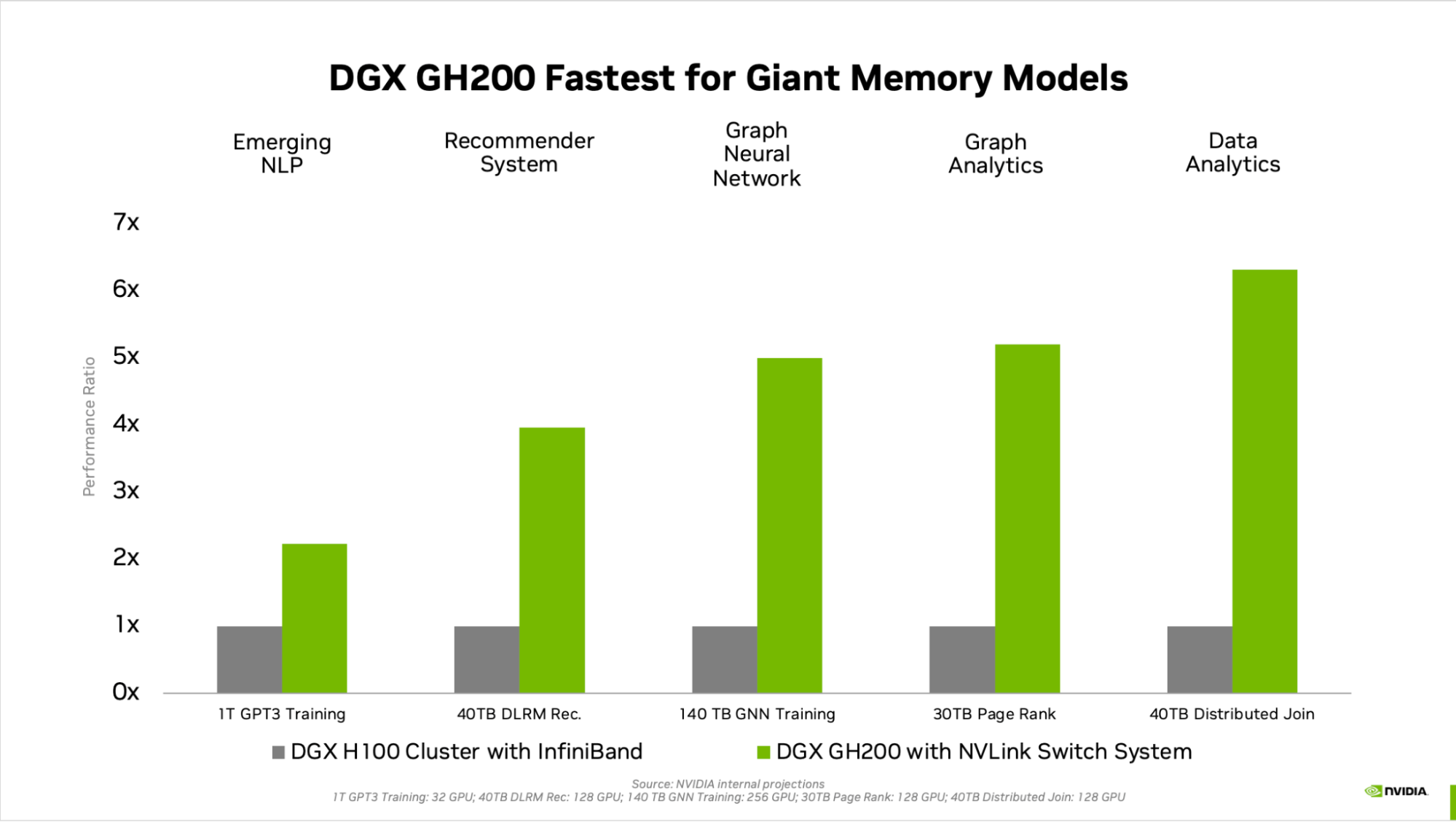
Рис. 2. Топология полностью подключенной системы коммутаторов NVIDIA NVLink на базе NVIDIA DGX GH200, состоящей из 256 графических процессоров. В системе DGX GH200 потоки графического процессора могут обращаться к одноранговой памяти HBM3 и LPDDR5X от других суперчипов Grace Hopper в сети NVLink, используя таблицу страниц NVLink. Библиотеки ускорения ввода-вывода NVIDIA Magnum оптимизируют обмен данными с графическим процессором для повышения эффективности, улучшая масштабирование приложений со всеми 256 графическими процессорами. Каждый суперчип Grace Hopper в DGX GH200 сопряжен с одним сетевым адаптером NVIDIA ConnectX-7 и одним сетевым адаптером NVIDIA BlueField-3 . DGX GH200 имеет полосу пропускания 128 ТБ/с и 230,4 терафлопс сетевых вычислений NVIDIA SHARP для ускорения коллективных операций, обычно используемых в ИИ, и удваивает эффективную пропускную способность сетевой системы NVLink за счет снижения коммуникационных издержек при коллективных операциях. Для масштабирования более 256 графических процессоров адаптеры ConnectX-7 могут соединять несколько систем DGX GH200 для масштабирования в еще большее решение. Мощь DPU BlueField-3 превращает любую корпоративную вычислительную среду в безопасное и ускоренное виртуальное частное облако, позволяя организациям выполнять рабочие нагрузки приложений в безопасных многопользовательских средах. Целевые варианты использования и преимущества производительностиСкачок между поколениями памяти графического процессора значительно повышает производительность приложений искусственного интеллекта и высокопроизводительных вычислений, узким местом которых является размер памяти графического процессора. Многие основные рабочие нагрузки искусственного интеллекта и высокопроизводительных вычислений могут полностью размещаться в совокупной памяти графического процессора одного NVIDIA DGX H100 . Для таких рабочих нагрузок DGX H100 является наиболее эффективным решением для обучения. Другие рабочие нагрузки, такие как рекомендательная модель глубокого обучения (DLRM) с терабайтами встроенных таблиц, модель обучения нейронной сети с графом масштаба терабайта или рабочие нагрузки аналитики больших данных, обеспечивают ускорение от 4 до 7 раз с DGX GH200. Это показывает, что DGX GH200 является лучшим решением для более продвинутых моделей искусственного интеллекта и высокопроизводительных вычислений, требующих большой памяти для программирования с общей памятью графического процессора. Механизм ускорения подробно описан в техническом описании архитектуры суперчипа NVIDIA Grace Hopper .
Рисунок 3. Сравнение производительности для гигантских рабочих нагрузок искусственного интеллекта памяти Специально разработан для самых ресурсоемких рабочих нагрузокКаждый компонент DGX GH200 выбран таким образом, чтобы свести к минимуму узкие места, максимально повысить производительность сети для ключевых рабочих нагрузок и полностью использовать все аппаратные возможности масштабирования. Результатом является линейная масштабируемость и высокая степень использования огромного пространства общей памяти. Чтобы получить максимальную отдачу от этой передовой системы, NVIDIA также разработала чрезвычайно высокоскоростную фабрику хранения для работы с максимальной емкостью и обработки различных типов данных (текст, табличные данные, аудио и видео) — параллельно и с неизменной скоростью. производительность. Полнофункциональное решение NVIDIADGX GH200 поставляется с NVIDIA Base Command , которая включает в себя ОС, оптимизированную для рабочих нагрузок ИИ, менеджер кластера, библиотеки, ускоряющие вычисления, хранилище и сетевую инфраструктуру, оптимизированную для системной архитектуры DGX GH200. DGX GH200 также включает в себя NVIDIA AI Enterprise , предоставляя набор программного обеспечения и сред, оптимизированных для оптимизации разработки и развертывания ИИ. Это комплексное решение позволяет клиентам сосредоточиться на инновациях и меньше беспокоиться об управлении своей ИТ-инфраструктурой.
Рис. 4. Полный стек ИИ-суперкомпьютера NVIDIA DGX GH200 включает NVIDIA Base Command и NVIDIA AI Enterprise Повышение производительности гигантских рабочих нагрузок ИИ и высокопроизводительных вычисленийNVIDIA работает над выпуском DGX GH200 в конце этого года. NVIDIA стремится предоставить этот невероятный первый в своем роде суперкомпьютер и дать вам возможность внедрять инновации и реализовывать свои увлечения в решении самых сложных современных задач в области искусственного интеллекта и высокопроизводительных вычислений. |
| ||||||||